18 系统复位(System Reset)
上一章
上一章描述了 PCIe 功能生成中断的不同方式。传统 PCI 模型使用引脚实现中断,但在串行模型中,边带信号并不理想,因此 PCIe 强制支持带内 MSI(Message Signaled Interrupt,消息信号中断)机制。出于软件向后兼容性的考虑,PCIe 仍可通过 INTx 消息模拟 PCI INTx# 引脚操作。上一章同时介绍了传统 PCI INTx# 方法以及较新的 MSI/MSI-X 机制。
本章
本章描述 PCIe 定义的四种复位类型:冷复位(Cold Reset)、温复位(Warm Reset)、热复位(Hot Reset)和功能级复位(Function-Level Reset,FLR)。本章还讨论了通过边带复位信号 PERST# 生成系统复位的方法,以及通过带内 TS1 有序集生成热复位的方法。
下一章
下一章将介绍 PCI Express 热插拔模型。同时,针对所有支持热插拔功能的设备和外形规格,也定义了一套标准使用模型。对于热插拔卡而言,功耗同样是一个关键问题。在系统运行期间添加新卡时,必须确保其功耗需求不超过系统能够提供的上限。因此,需要一种机制来查询并控制设备的功耗需求,电源预算管理(Power Budgeting)正是为此提供的解决方案。
18.1 系统复位的两类方式(Two Categories of System Reset)
PCI Express 规范描述了四种复位机制。其中三种机制源自 PCIe 规范的早期修订版本,现在统称为常规复位(Conventional Resets);其中两种又被称为基本复位(Fundamental Resets)。第四种复位类别和复位方法是在 2.0 规范修订版中新增的,称为功能级复位(Function-Level Reset,FLR)。
18.2 常规复位(Fundamental Reset)
18.2.1 基本复位(Fundamental Reset)
基本复位(Fundamental Reset)由硬件处理,会复位整个设备,并重新初始化所有状态机、硬件逻辑、端口状态以及配置寄存器。例外是一组被标记为“粘滞”(Sticky)的配置寄存器字段:除非所有电源都被移除,否则这些字段会保留原有内容。这对于诊断那些必须通过复位才能重新建立链路的问题非常有用,因为错误状态可以跨复位保留下来,之后仍可由软件读取。如果主电源被移除但 Vaux 辅助电源仍然可用,粘滞位也会保持;但如果主电源和 Vaux 都丢失,粘滞位会与其他状态一起被复位。
基本复位会在系统级复位时发生,也可以针对单个设备执行。
基本复位定义了两种类型:
- 冷复位(Cold Reset):设备主电源开启时产生的复位。断电后重新上电会导致冷复位。
- 温复位(Warm Reset,可选):通过系统特定方式触发,但不关闭主电源。例如,系统电源状态变化可能用于发起温复位。规范未定义温复位的具体生成机制,因此由系统设计者自行选择实现方式。
当发生基本复位时:
- 对于正电压,接收端端接需要满足
ZRX-HIGH-IMP-DC-POS参数。在 2.5 GT/s 条件下,该值不低于 10 kΩ;在更高速率下,当电压低于 200 mV 时不低于 10 kΩ,当电压高于 200 mV 时不低于 20 kΩ。这些数值适用于端接未通电的情况。 - 对于负电压,
ZRX-HIGH-IMP-DC-NEG参数在所有情况下的最小值均为 1 kΩ。 - 发送端端接需要满足输出阻抗
ZTX-DIFF-DC:Gen1 为 80 Ω 至 120 Ω,Gen2 和 Gen3 最大为 120 Ω;但发送器也可以将驱动器置于高阻抗状态。 - 发送器保持 0 V 至 3.6 V 的直流共模电压。
从基本复位退出时:
- 当接收端端接启用时,必须存在接收端单端端接,以确保接收器检测(Receiver Detect)能够正常工作。Gen1 和 Gen2 为 40 Ω 至 60 Ω,Gen3 为 50 Ω ±20%。进入 Detect 状态时,共模阻抗必须处于 50 Ω ±20% 的适当范围内。
- 必须在基本复位退出后的 5 ms 内重新启用接收端端接
ZRX-DIFF-DC(100 Ω),以便在训练期间能被相邻发送器检测到。 - 发送器保持 0 V 至 3.6 V 的直流共模电压。
规范定义了两种传递基本复位的方法。第一种是通过名为 PERST#(PCI Express Reset)的辅助边带信号触发。第二种是当 PCIe 插卡或组件未接收到 PERST# 信号时,在电源循环通断后,由组件或插卡自主生成基本复位。
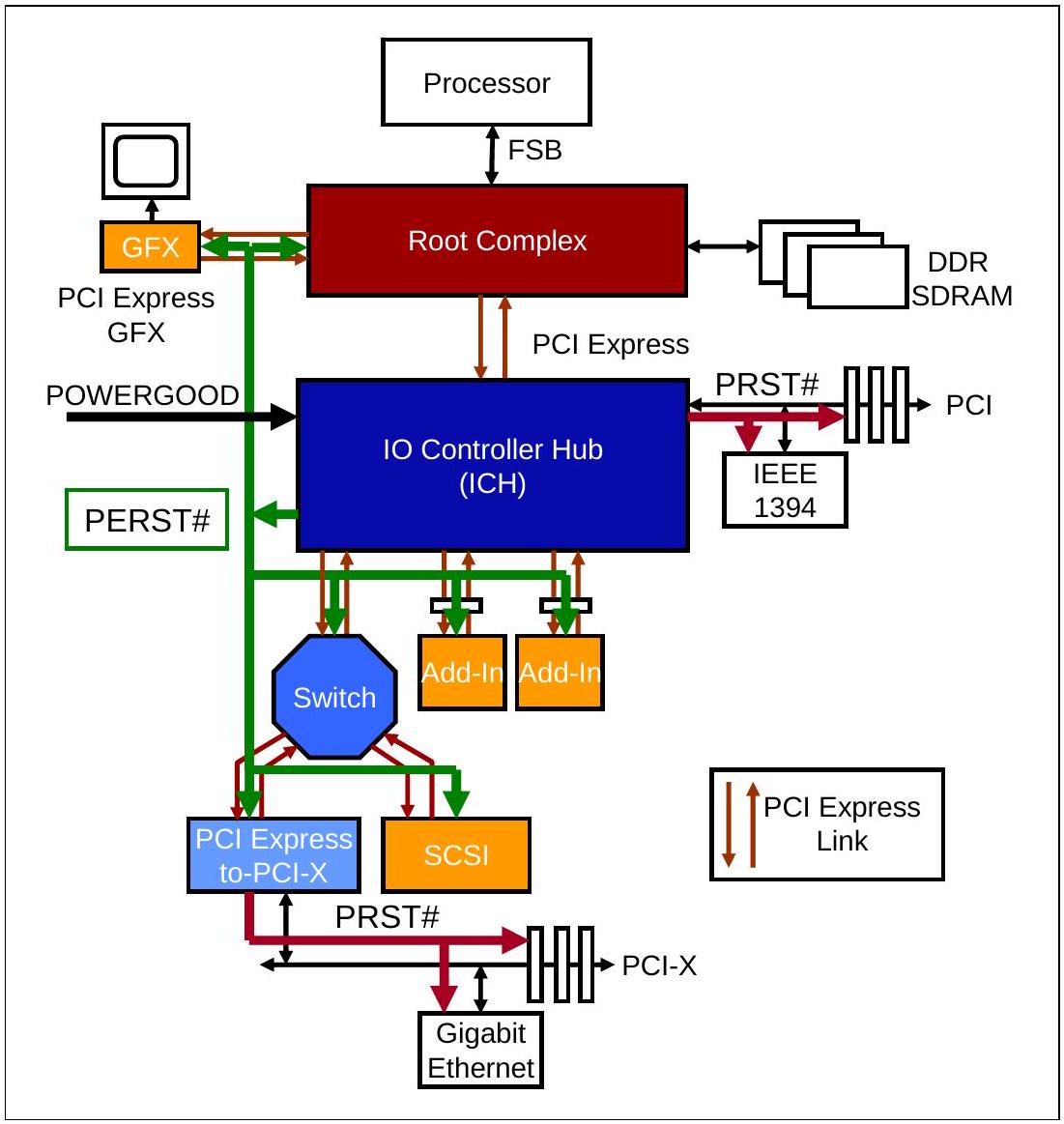
18.2.1.1 PERST# 基本复位生成机制
PCI Express 系统中的中央资源设备(例如芯片组)负责提供 PERST#
复位信号。例如,图 18-1 中的 I/O Controller
Hub(ICH)芯片可以根据系统电源 POWERGOOD
信号的状态生成
PERST#,因为该信号表示主电源已经开启且稳定。如果电源先关闭再重新开启,POWERGOOD
会发生电平跳变,使 PERST#
先置位再取消置位,从而产生冷复位。系统也可以通过其他方式切换
PERST# 信号,以实现温复位。
PERST# 信号会送到主板上的所有 PCI Express 设备,包括连接器和图形控制器。设备可以选择使用 PERST#,但并非强制要求。图中所示的 PERST# 信号也会送到 PCIe-to-PCI-X 桥接器。桥接器始终会将其主侧(Primary,上游)总线上的复位转发到次侧(Secondary,下游)总线,因此 PCI-X 总线会看到 RST# 被断言。
18.2.1.2 自主复位生成
设备必须设计为在主电源施加时,通过硬件自主生成复位。规范没有规定具体实现方式,因此自复位机制可以内置于设备中,也可以通过外部逻辑实现。例如,检测到上电事件的附加卡可以利用该事件为其设备生成本地复位。如果设备检测到其供电超出规范限定范围,也必须自主生成复位。
18.2.1.3 从 L2 低功耗状态唤醒链路
作为自主复位需求的一个示例,某个设备可能因为电源管理策略而被关闭主电源;如果该设备设计为能够发出唤醒信号,那么它可能请求系统恢复全功率状态。当电源恢复时,设备必须复位。系统电源控制器可能会向该设备断言 PERST#,如图 18-1 所示;但如果系统没有提供该信号,或者设备不支持 PERST#,那么设备在检测到主电源重新施加时,必须自主生成自己的基本复位。
图 18-1:PERST# 生成
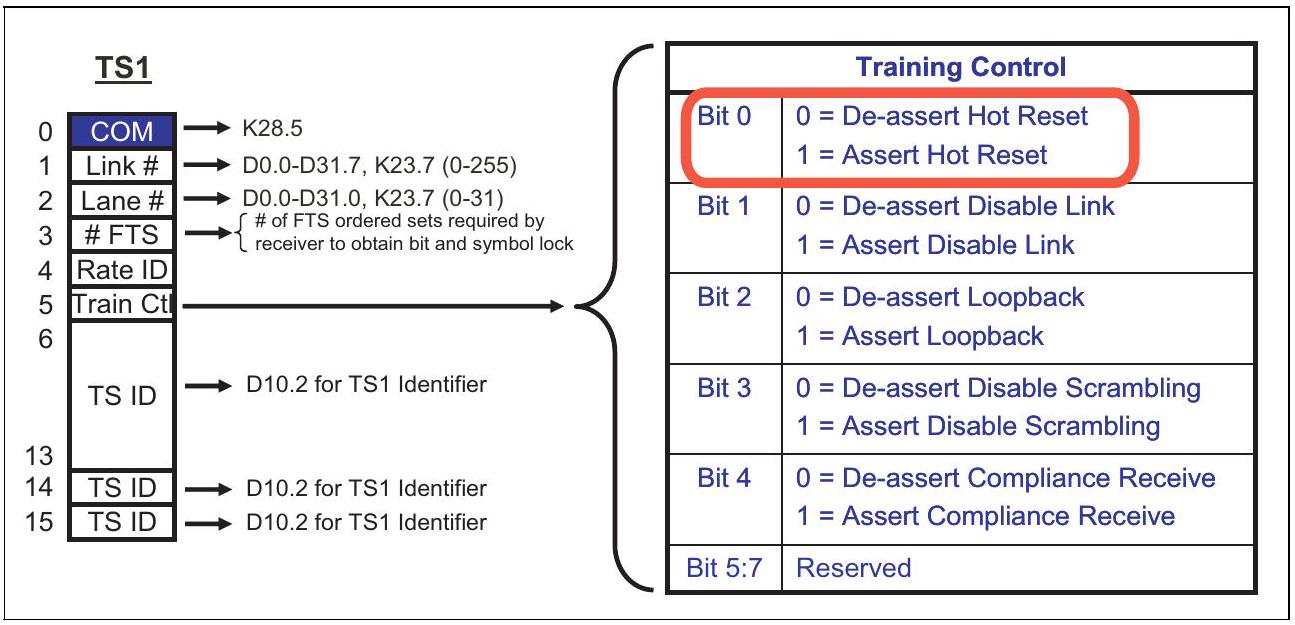
18.2.2 热复位(带内复位)(Hot Reset (In-band Reset))
热复位(Hot Reset,也称带内复位,In-band Reset)通过在相邻链路伙伴之间发送 TS1 有序集传播。用于热复位的 TS1 如图 18-2 所示,其 Symbol 5 的 bit 0 被置位。这些 TS1 会在所有 Lane 上发送,并使用此前协商好的 Link Number 和 Lane Number,持续发送 2 ms。发送完成后,热复位的发送端和接收端最终都会进入 Detect LTSSM 状态。
图 18-2:显示 Hot Reset 位的 TS1 有序集
热复位由软件通过设置桥接器 Bridge Control 配置寄存器中的 Secondary Bus Reset 位发起,如图 18-5 所示。因此,只有包含桥结构的设备(例如 Root Complex 或 Switch)才能发起热复位。Switch 如果在其上游端口接收到热复位,必须将其广播到所有下游端口,并复位自身。Switch 下游所有接收到热复位的设备都会复位自身。
18.2.2.1 接收热复位后的响应
- 设备的 LTSSM 会经过 Recovery 状态和 Hot Reset 状态,然后返回 Detect 状态,并在 Detect 状态下开始链路训练过程。
- 设备的所有状态机、硬件逻辑、端口状态和配置寄存器都会初始化为默认状态,粘滞寄存器除外。
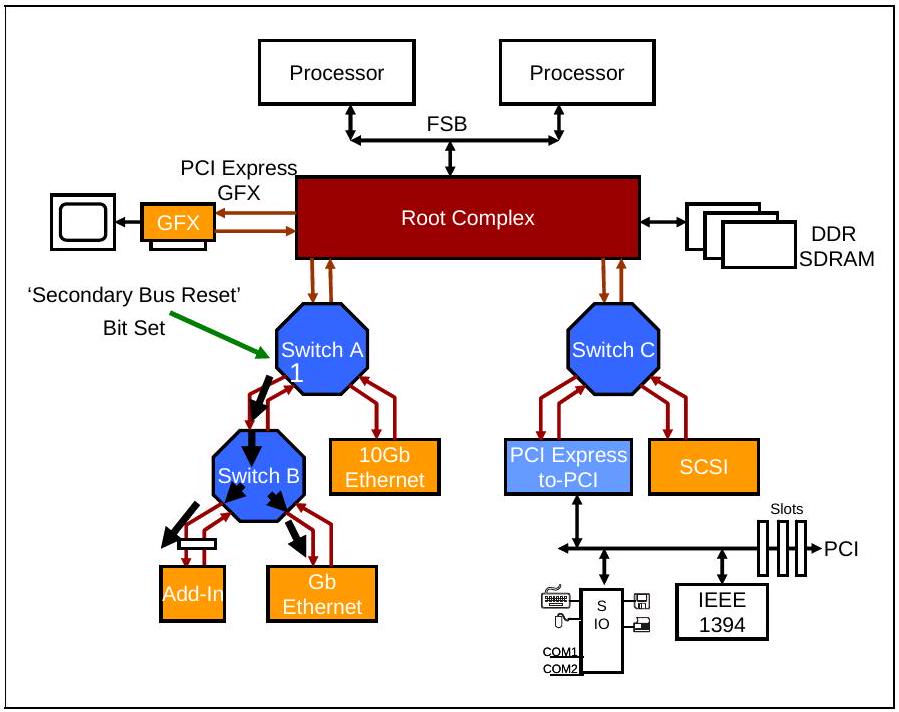
18.2.2.2 Switch 在下游端口上生成热复位
当满足以下条件之一时,Switch 会在其所有下游端口上生成热复位:
- Switch 在其上游端口接收到热复位。
- 对于 Switch 或桥接器的上游端口,如果数据链路层报告
DL_Down状态,其效果与热复位非常相似。这种情况可能发生在上游端口由于物理层或数据链路层无法恢复的错误而失去与上游设备的连接时。 - 软件设置与上游端口关联的 Bridge Control 配置寄存器中的 Secondary Bus Reset 位,如图 18-3 所示。
图 18-3:Switch 在一个下游端口上生成热复位
18.2.2.3 桥接器将热复位转发到次级总线
如果某个桥接器(例如 PCI Express-to-PCI/PCI-X 桥接器)在其上游端口检测到热复位,则必须在其次级 PCI/PCI-X 总线上断言 PRST# 信号,如图 18-4 所示。
18.2.2.4 软件生成热复位
软件通过向相关端口配置头的 Bridge Control 寄存器中的 Secondary Bus Reset 位先写入 1、再写入 0,在特定端口上生成热复位(参见图 18-5)。以图 18-3 的示例为例,软件设置 Switch A 左侧下游端口的 Secondary Bus Reset 位,使其发送 Hot Reset 位被置位的 TS1 有序集。Switch B 在其上游端口接收到该热复位后,会将其转发到所有下游端口。
图 18-4:Switch 在所有下游端口生成热复位
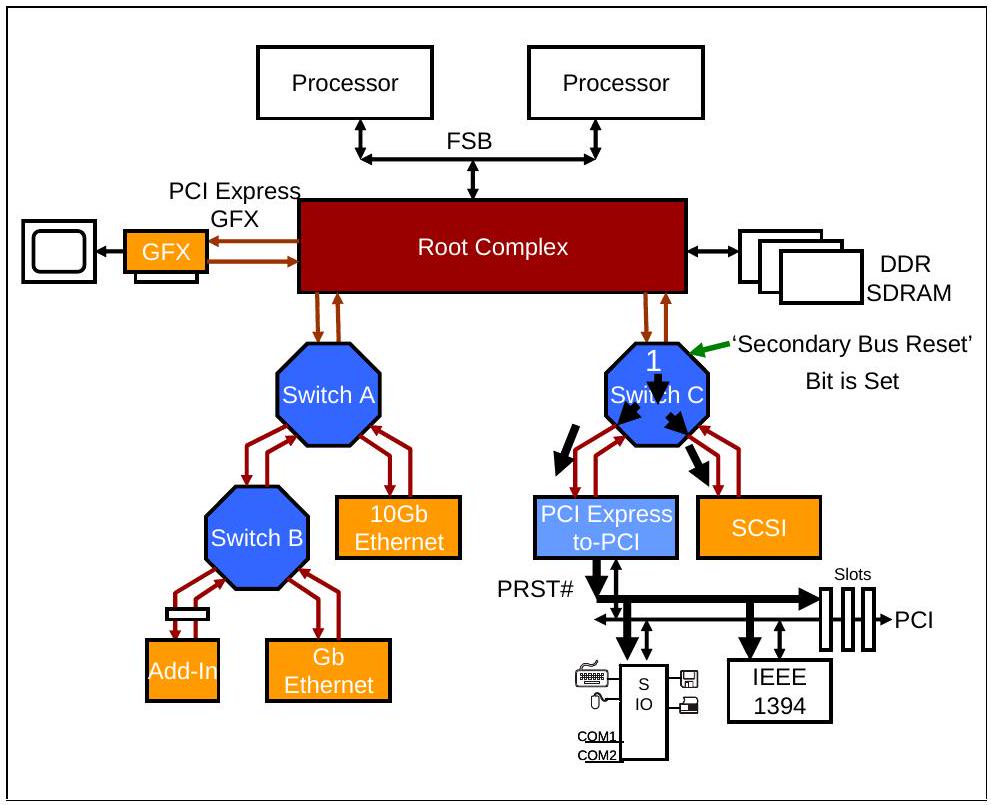
如果软件设置 Switch 上游端口的 Secondary Bus Reset 位,则该 Switch 会在其所有下游端口上生成热复位,如图 18-4 所示。在该图中,软件设置 Switch C 上游端口的 Secondary Bus Reset 位,使其在所有下游端口发送 Hot Reset 位被置位的 TS1。PCIe-to-PCI 桥接器接收到此热复位后,会通过断言 PRST# 将复位转发到 PCI 总线。
设置 Secondary Bus Reset 位会使端口的 LTSSM 转换到 Recovery 状态,在该状态下生成 Hot Reset 位被置位的 TS1。TS1 会连续发送 2 ms,然后该端口退出到 Detect 状态,准备开始链路训练过程。
Hot Reset TS1 的接收端(始终是下游端)也会进入 Recovery 状态。当它连续检测到两个 Hot Reset 位被置位的 TS1 时,会进入 Hot Reset 状态并保持 2 ms 超时,然后退出到 Detect 状态。上游端口和下游端口都会被初始化,并最终进入 Detect 状态,准备重新开始链路训练。如果下游设备本身也是 Switch 或桥接器,它还会将 Hot Reset 转发到自己的下游端口,如图 18-3 所示。
图 18-5:用于生成 Hot Reset 的 Secondary Bus Reset 寄存器
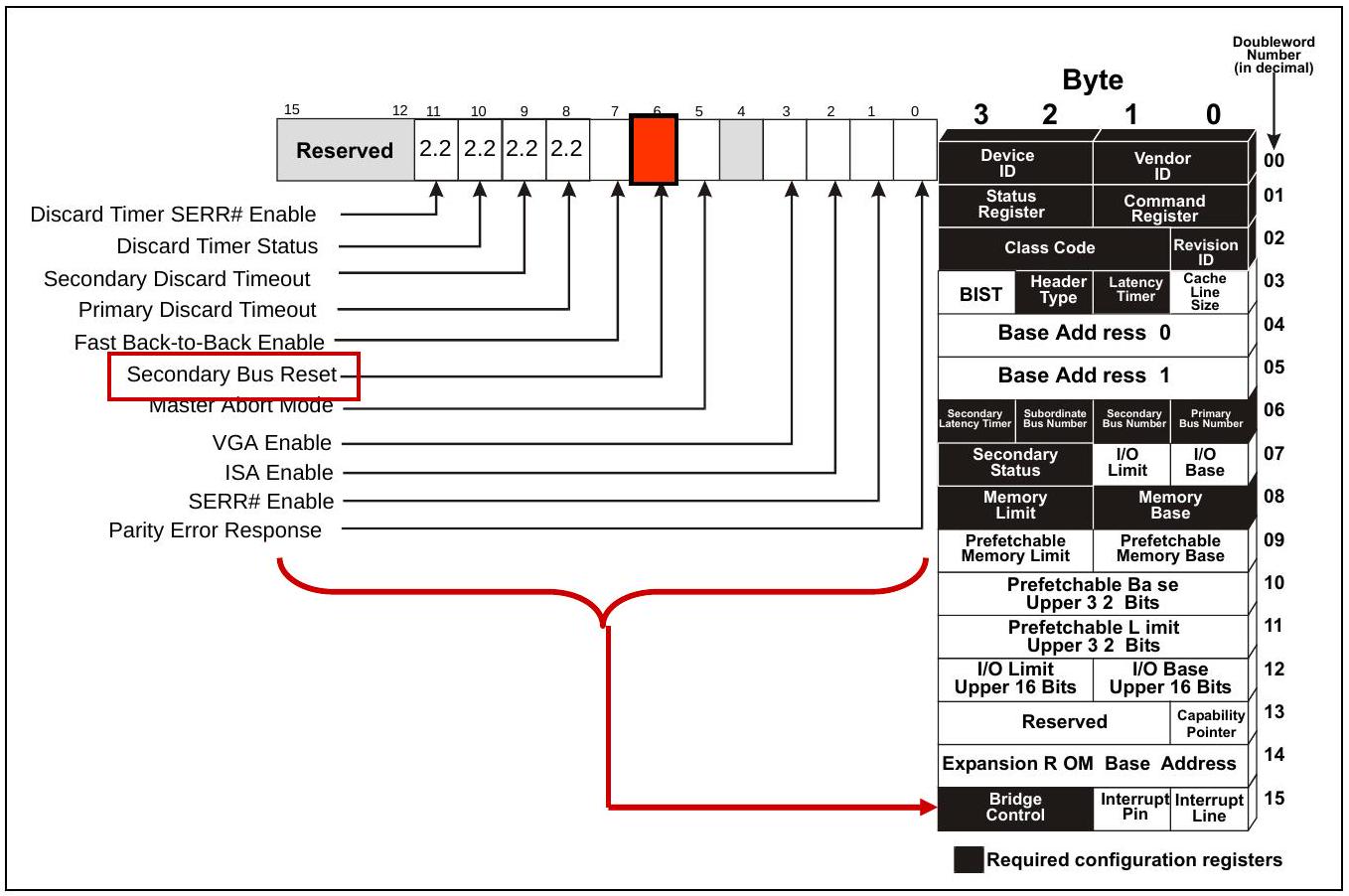
18.2.2.5 软件可以禁用链路
软件也可以禁用一条链路,强制其进入 Electrical Idle 并保持该状态,直到收到进一步指示。这里之所以提到这一点,是因为禁用链路也会导致下游组件发生热复位。禁用操作通过设置下游端口 Link Control Register 中的 Link Disable 位完成,如图 18-6 所示。这会使端口进入 Recovery LTSSM 状态,并开始发送 Disable 位被置位的 TS1。由于只有下游端口才能控制链路禁用,因此该位在上游端口(例如 Endpoint 或 Switch Upstream Port)中为保留位。
图 18-6:Link Control Register
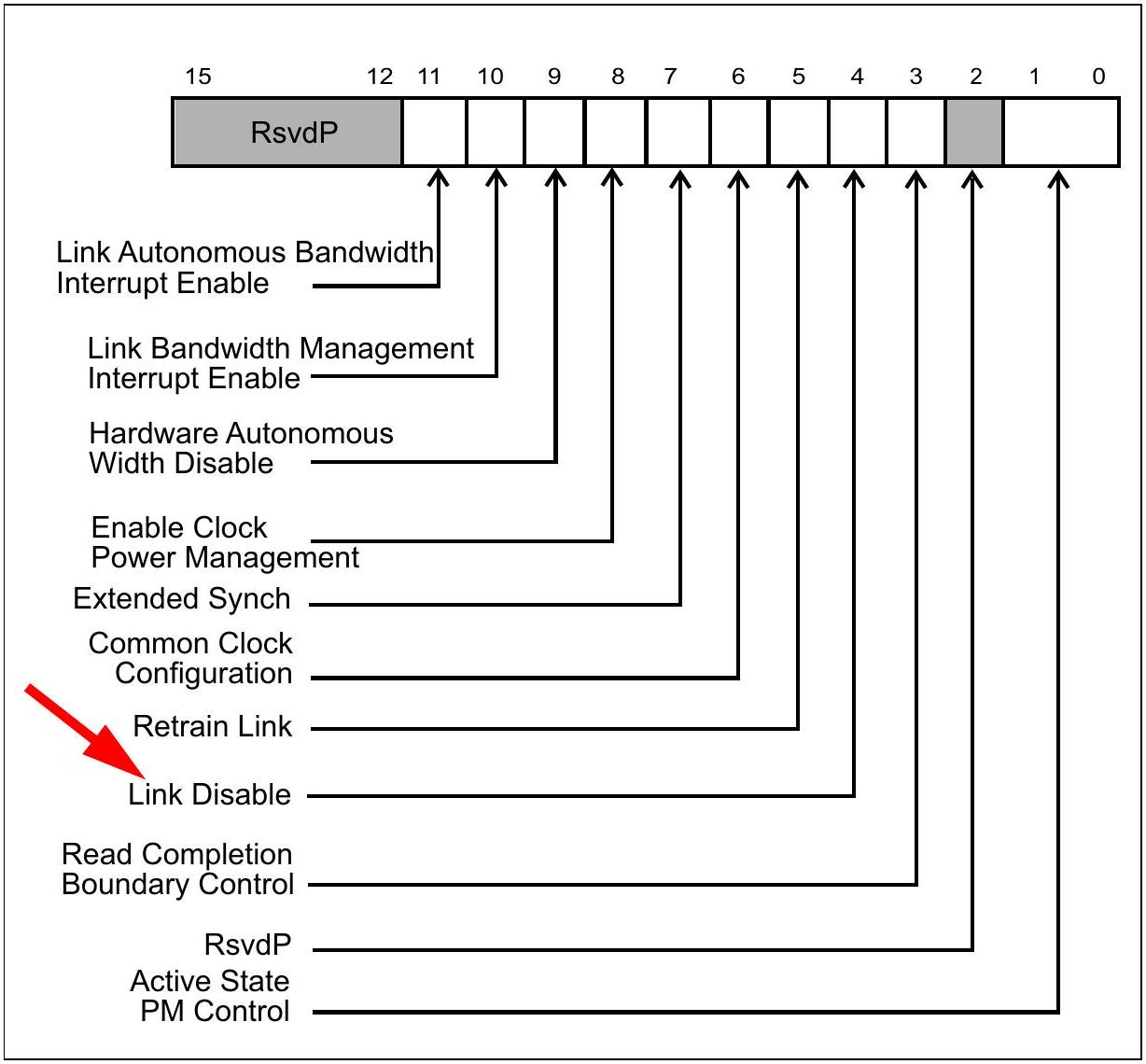
当上游端口识别到接收的 TS1 中 Disable
位被置位时,其物理层会向链路层发送
LinkUp = 0(false)信号,并且所有 Lane 进入
Electrical Idle。经过 2 ms 超时后,上游端口会进入 Detect
状态;但下游端口会保持在 Disabled LTSSM
状态,直到收到退出该状态的指示,例如清除 Link Disable
位。因此,链路会保持禁用状态,在此期间不会尝试训练。
图 18-7:显示 Disable Link 位的 TS1 有序集

18.3 功能级复位(FLR)(Function Level Reset)
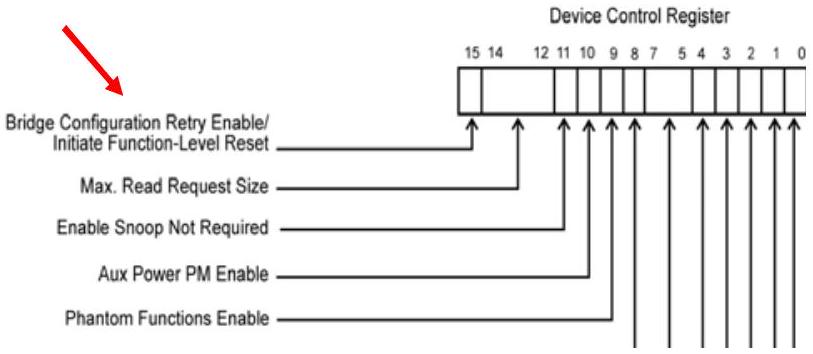
功能级复位(Function-Level Reset,FLR)允许软件仅复位多功能设备中的某一个 Function,而不影响所有 Function 共享的链路。规范强烈建议实现 FLR,但并不强制要求。因此,软件在尝试使用 FLR 前,需要先检查 Device Capabilities Register(如图 18-8 所示),确认该能力是否存在。如果 Function-Level Reset Capability 位被置位,则软件只需设置 Device Control Register 中的 Initiate Function-Level Reset 位(如图 18-9 所示),即可发起 FLR。
图 18-8:Function-Level Reset Capability
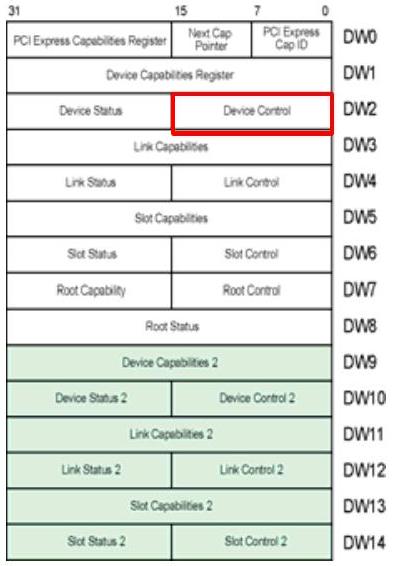
图 18-9:Function-Level Reset Initiate Bit
规范列举了几个推动 FLR 功能加入的示例:
- 控制某个 Function 的软件可能遇到问题,导致无法正常运行。为了防止数据损坏,需要复位该 Function;但如果同一设备中的其他 Function 仍然工作正常,那么只复位出现问题的 Function 会更理想。
- 在虚拟化环境中,应用程序可以从一个硬件迁移到另一个硬件。当应用程序从某个 Function 迁移出去后,必须确保该 Function 不保留任何关于先前操作的信息。这可以防止某个应用程序使用过、可能被视为机密的信息,被后续运行在该 Function 上的新应用程序看到。迁移前一个应用程序后,最简单的清理方法就是复位该 Function。
- 当软件为某个 Function 重建软件栈时,有时需要先将该 Function 放回未初始化状态。与前面类似,避免复位共享同一条链路的所有 Function 是有价值的。
规范列出的示例中没有包含另一个特性,但该特性本身也是 FLR 的重要驱动因素。常规复位会重新初始化设备内部的所有状态,但并不要求所有外部活动(例如网络接口上的流量)必须立即停止。FLR 增加了这一要求,并且是唯一具备该要求的复位方式。
FLR 会复位 Function 的内部状态和寄存器,使其进入静默状态(Quiescent),但不会影响粘滞位、硬件初始化位,或链路特定寄存器,例如 Captured Power、ASPM Control、Max Payload Size 和 Virtual Channel 寄存器。如果该 Function 之前发送过尚未解除的 Assert INTx 中断消息,则必须发送相应的 Deassert INTx 消息,除非该中断在设备内部被另一个仍保持断言状态的 Function 共享。当接收到 FLR 时,该 Function 的所有外部活动都必须停止。
18.3.1 允许时间
一个 Function 必须在 100 ms 内完成 FLR。不过,如果存在尚未返回的未完成拆分完成事务(Outstanding Split Completions),软件可能需要延迟发起 FLR。这种情况可以通过 Device Status Register 中仍处于置位状态的 Transactions Pending 位来判断。在这种情况下,软件必须等待这些事务完成后再发起 FLR,或者在 FLR 之后等待 100 ms 再尝试重新初始化该 Function。
如果没有妥善处理这一点,可能产生数据损坏风险:Function 可能仍有未完成的拆分事务,但复位导致它丢失了对这些事务的跟踪。如果这些事务稍后返回,可能会被误认为是 FLR 之后新发出请求的响应。为了避免此问题,规范建议软件执行以下步骤:
- 与其他可能访问该 Function 的软件协调,确保 FLR 期间不会尝试访问该 Function。
- 清除整个 Command Register,使该 Function 进入静默状态。
- 通过轮询 Device Status Register 中的 Transactions Pending 位,确认此前请求对应的 Completion 已返回;持续等待直到该位清零,或等待足够长的时间以确认 Completion 不会再返回。多长时间才算足够长?如果启用了 Completion Timeout 机制,则在发送 FLR 前等待该超时时间;如果禁用了 Completion Timeout,则至少等待 100 ms。
- 发起 FLR 并等待 100 ms。
- 配置该 Function 的配置寄存器,并启用其正常操作。
FLR 完成后,无论具体时序如何,Transactions Pending 位都必须被清除。
18.3.2 FLR 期间的行为
规范编写者以相当宽泛的方式描述 Function Reset 的行为,以避免限制设计者可能希望采用的内部步骤。规范列出了以下行为要求:
- Function 不得在外部接口上表现为一个已经初始化、且具有活动主机的适配器。确保所有外部接口活动都终止的具体步骤因设计而异。例如,网络适配器在此期间不得响应需要活动主机参与的请求。
- Function 不得保留任何可能包含先前使用该 Function 时遗留机密信息的软件可读状态。例如,所有内部存储器都必须被清零或随机化。
- Function 必须能够被下一个驱动程序正常配置。
- Function 必须先为触发 FLR 的配置写请求返回 Completion,然后再启动 FLR。
当 FLR 正在进行时:
- 任何到达的请求都可以被静默丢弃,不需要记录日志,也不需要发出错误信号。不过,仍必须更新流量控制信用值,以维持链路运行。
- 传入的 Completion 可以被视为 Unexpected Completion,也可以被静默丢弃,不需要记录日志或发出错误信号。
- FLR 本身必须在前述时间内完成,但此后的进一步初始化可能需要更长时间。如果初始化完成前收到配置请求,该 Function 必须返回带有 CRS(Configuration Retry Status,配置重试状态)的 Completion。一旦返回任何其他状态的 Completion,在该 Function 再次被复位之前,CRS 状态就不再合法。
18.4 复位退出(Reset Exit)
退出复位状态后,链路训练与初始化必须在 20 ms 内开始。由于复位信号是异步的,不同设备退出复位状态的时间可能不同,但它们都必须在该时间范围内开始训练。
为了允许被复位组件执行内部初始化,系统软件在复位结束后必须至少等待 100 ms,才能尝试向这些组件发送配置请求。如果软件在 100 ms 等待期后向设备发起配置请求,但设备仍未完成自初始化,则设备会返回 CRS 状态的 Completion。由于配置请求只能由 CPU 发起,该 Completion 会返回至 Root Complex。Root Complex 可以据此自动重新发起配置请求,也可以向软件报告失败状态。规范同时指出,软件只有在启用了 CRS Software Visibility 功能时才应使用 100 ms 等待周期,否则可能导致长时间超时或处理器停滞。
设备在复位后可以有完整的 1.0 s(-0%/+50%)时间,之后才必须对配置请求给出正确响应。因此,系统必须谨慎等待足够长的时间,才能判定无响应设备已经损坏。该值继承自 PCI,之所以存在如此长的延迟,可能是因为某些设备将配置空间实现为本地存储器,而该存储器必须先完成初始化,配置软件才能正确读取。该初始化过程可能涉及从低速串行 EEPROM 复制必要信息,因此可能需要一些时间。